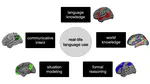
Large language models (LLMs) have come closest among all models to date to mastering human language, yet opinions about their capabilities remain split. Here, we evaluate LLMs using a distinction between formal competence — knowledge of linguistic rules and patterns — and functional competence — understanding and using language in the world. We ground this distinction in human neuroscience, showing that these skills recruit different cognitive mechanisms. Although LLMs are close to mastering formal competence, they still fail at functional competence tasks, which often require drawing on non-linguistic capacities. In short, LLMs are good models of language but incomplete models of human thought.
Kyle Mahowald, Anna (Anya) Ivanova, Idan A Blank, Nancy Kanwisher, Josh Tenenbaum, Evelina Fedorenko