Dissociating language and thought in large language models: a cognitive perspective
 Language use requires not only language-specific, but also general cognitive abilities.
Language use requires not only language-specific, but also general cognitive abilities.Abstract
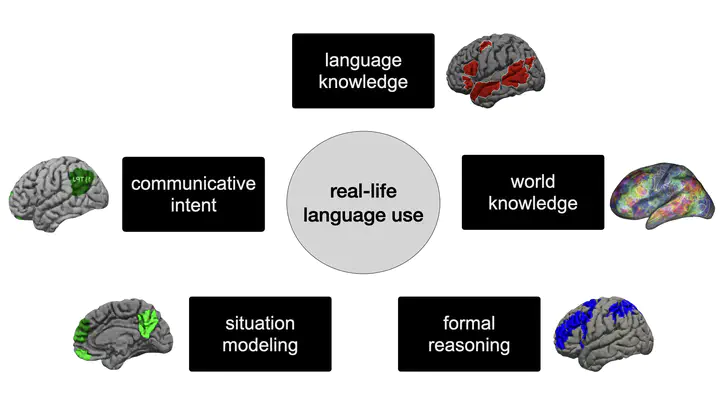
Today, large language models (LLMs) routinely generate coherent, grammatical and seemingly meaningful paragraphs of text. This achievement has led to speculation that these networks are - or will soon become - “thinking machines”, capable of performing tasks that require abstract knowledge and reasoning. Here, we review the capabilities of LLMs by considering their performance on two different aspects of language use: “formal linguistic competence”, which includes knowledge of rules and patterns of a given language, and “functional linguistic competence”, a host of cognitive abilities required for language understanding and use in the real world. Drawing on evidence from cognitive neuroscience, we show that formal competence in humans relies on specialized language processing mechanisms, whereas functional competence recruits multiple extralinguistic capacities that comprise human thought, such as formal reasoning, world knowledge, situation modeling, and social cognition. In line with this distinction, LLMs show impressive (although imperfect) performance on tasks requiring formal linguistic competence, but fail on many tests requiring functional competence. Based on this evidence, we argue that (1) contemporary LLMs should be taken seriously as models of formal linguistic skills; (2) models that master real-life language use would need to incorporate or develop not only a core language module, but also multiple non-language-specific cognitive capacities required for modeling thought. Overall, a distinction between formal and functional linguistic competence helps clarify the discourse surrounding LLM potential and provides a path toward building models that understand and use language in human-like ways.