Beyond linear regression: mapping models in cognitive neuroscience should align with research goals
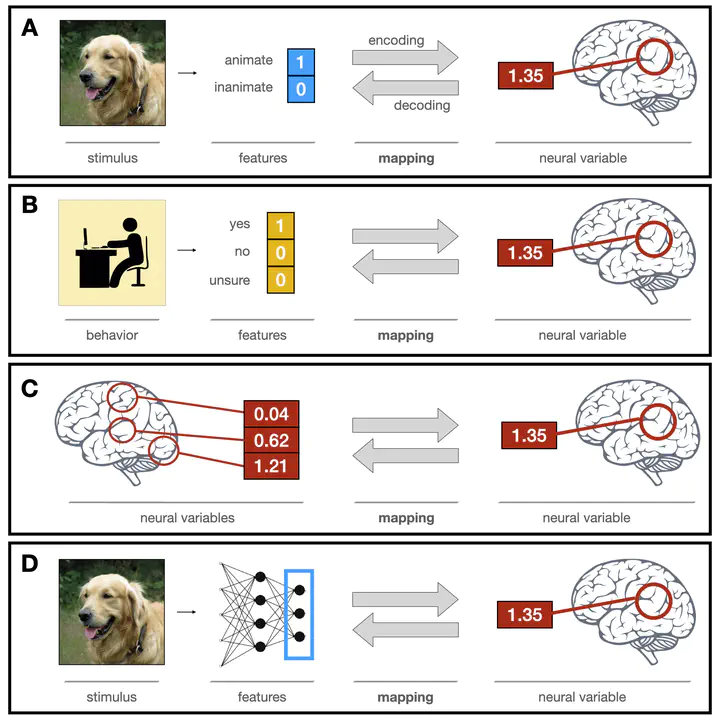 The encoding/decoding modeling framework in cognitive neuroscience.
The encoding/decoding modeling framework in cognitive neuroscience.Abstract
Many cognitive neuroscience studies use large feature sets to predict and interpret brain activity patterns. Feature sets take many forms, from human stimulus annotations to representations in deep neural networks. Of crucial importance in all these studies is the mapping model, which defines the space of possible relationships between features and neural data. Until recently, most encoding and decoding studies have used linear mapping models. Increasing availability of large datasets and computing resources has recently allowed some researchers to employ more flexible nonlinear mapping models instead; however, the question of whether nonlinear mapping models can yield meaningful scientific insights remains debated. Here, we discuss the choice of a mapping model in the context of three overarching desiderata: predictive accuracy, interpretability, and biological plausibility. We show that, contrary to popular intuition, these desiderata do not map cleanly onto the linear/nonlinear divide; instead, each desideratum can refer to multiple research goals, each of which imposes its own constraints on the mapping model. Moreover, we argue that, instead of categorically treating the mapping models as linear or nonlinear, we should instead aim to estimate the complexity of these models. We show that, in many cases, complexity provides a more accurate reflection of restrictions imposed by various research goals. Finally, we outline several complexity metrics that can be used to effectively evaluate mapping models.