Anna (Anya) Ivanova
Assistant Professor
Georgia Institute of Technology
Hi!
I am an Assistant Professor of Psychology at Georgia Institute of Technology, interested in studying the relationship between language and other aspects of human cognition. In my work, I use tools from cognitive neuroscience (such as fMRI) and artificial intelligence (such as large language models).
To learn more, browse my lab’s website (Language, Intelligence, and Thought) or check out this 5-min TEDx talk about applying insights from neuroscience to better understand the capabilities of large language models.
You can contact me at a.ivanova [at] gatech [dot] edu or follow me on Twitter.
Interests
- Neuroscience of language and cognition
- The link between language and world knowledge in humans and in AI models
- Inner speech
Education
PhD in Brain & Cognitive Sciences, 2022
Massachusetts Institute of Technology
BS in Neuroscience & Computer Science, 2017
University of Miami
Position
Assistant Professor of Psychology
- Head of the Language, Intelligence, and Thought (LIT) lab
- Leveraging experimental tools to jointly analyze biological and artificial intelligence
Postdoctoral Associate
- Developing a large-scale benchmark to evaluate world knowledge in language models
- Designing a platform to enable all researchers to study world knowledge in machines using custom tests / models
Featured Publications
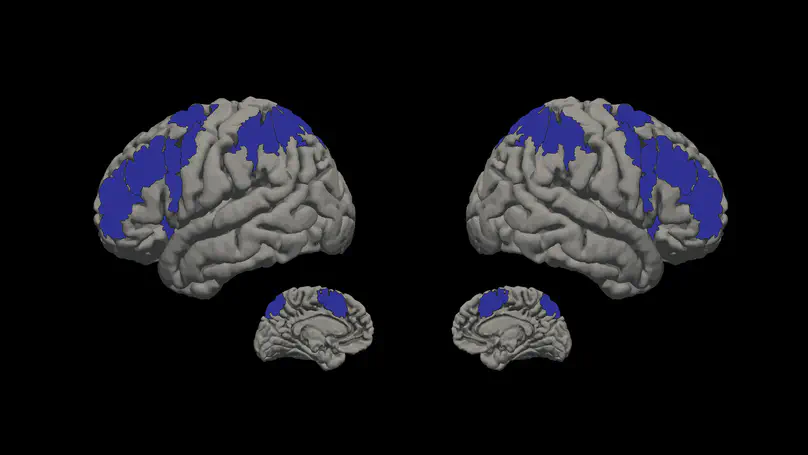
All Publications
Quickly discover relevant content by filtering publications.
(2023).
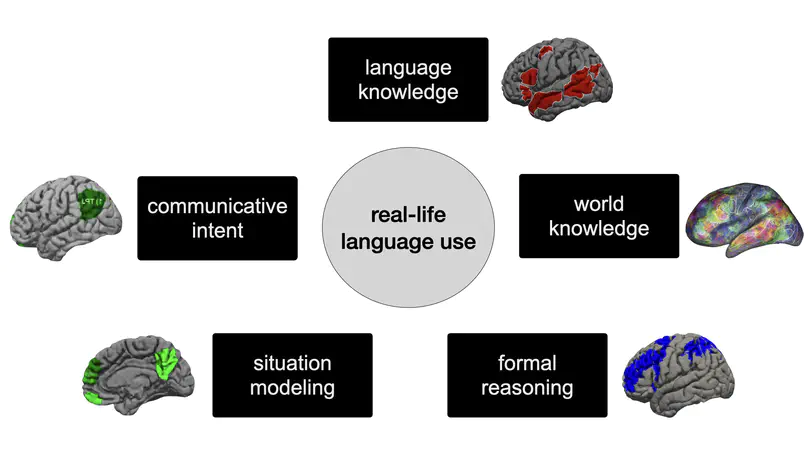
The language network is not engaged in object categorization.
Cerebral Cortex.
(2023).
A Better Way to Do Masked Language Model Scoring.
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL).
(2022).
Convergent Representations of Computer Programs in Human and Artificial Neural Networks.
Advances in Neural Information Processing Systems (NeurIPS).
(2022).
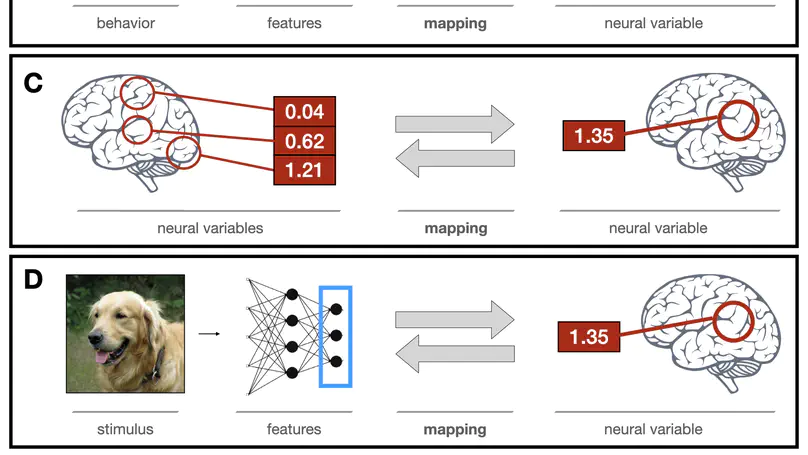
Beyond linear regression: mapping models in cognitive neuroscience should align with research goals.
Neurons, Behavior, Data analysis, and Theory.
(2022).
Probabilistic atlas for the language network based on precision fMRI data from >800 individuals.
Scientific Data.
(2021).
Probing artificial neural networks: Insights from neuroscience.
ICLR 2021 Workshop ``How Can Findings About The Brain Improve AI Systems?’'.
(2021).
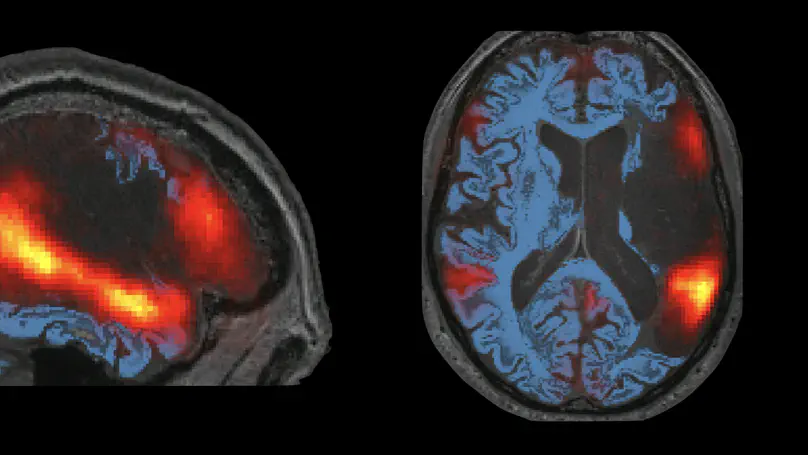
The language network is recruited but not required for nonverbal event semantics.
Neurobiology of Language.
(2020).
Comprehension of computer code relies primarily on domain-general executive brain regions.
eLife.
(2020).
Linguistic overhypotheses in category learning: Explaining the label advantage effect.
Proceedings of the 42nd Annual Conference of the Cognitive Science Society.
(2019).
The language of programming: a cognitive perspective.
Trends in Cognitive Sciences.
(2018).
Does the brain represent words? An evaluation of brain decoding studies of language understanding.
Computational Cognitive Neuroscience Conference.
(2018).
Pragmatic inference of intended referents from binomial word order.
Proceedings of the 40th Annual Conference of the Cognitive Science Society.
(2017).
Intrinsic functional organization of putative language networks in the brain following left cerebral hemispherectomy.
Brain Structure and Function.
(2014).
Post-fire succession in the northern pine forest in Russia: a case study.
Wulfenia.